Guide d'implémentation du service A2A basé sur le framework BeeAI
Aperçu
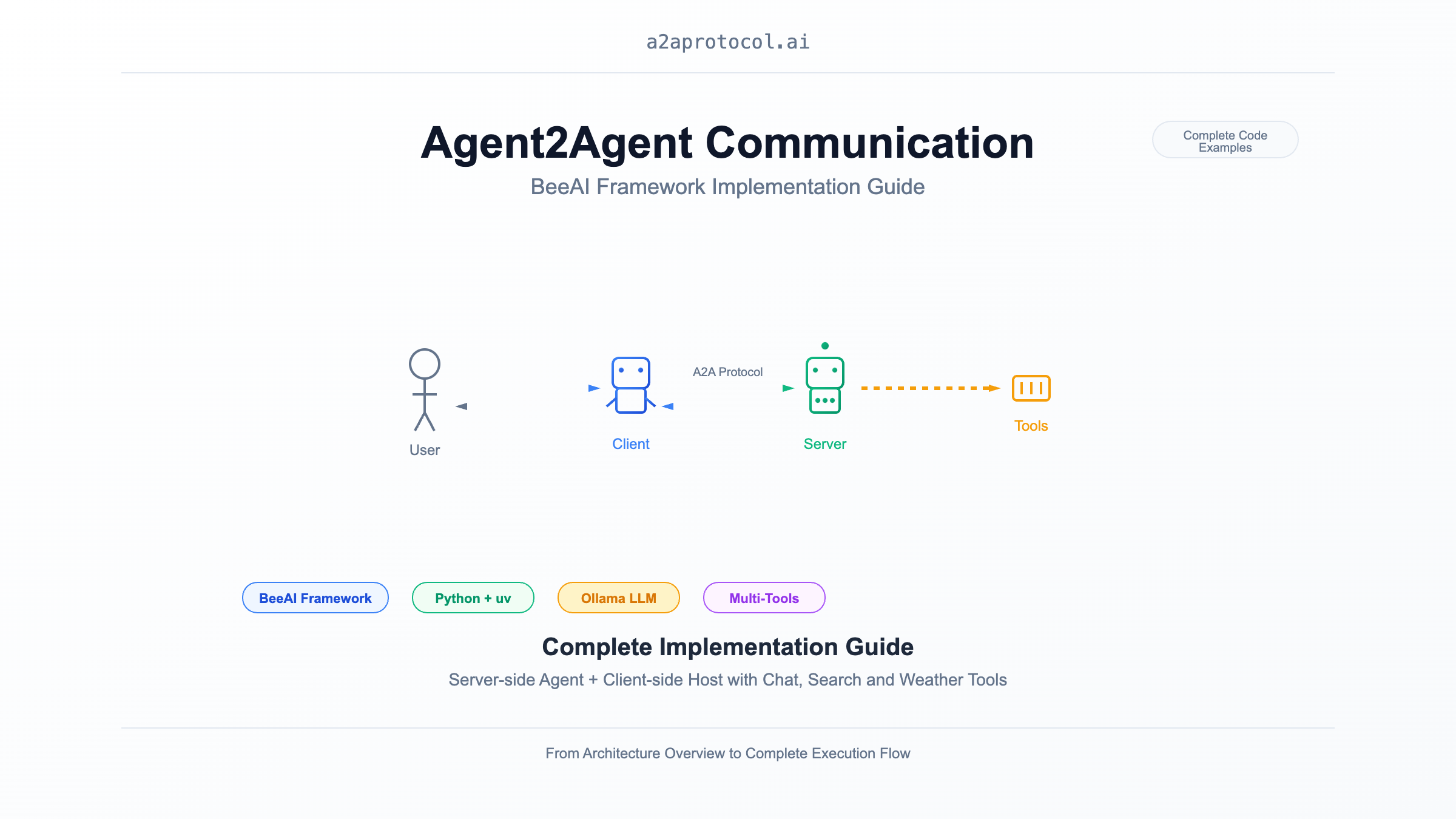
Ce document démontre comment implémenter la communication Agent2Agent (A2A) en utilisant le framework BeeAI, incluant les implémentations complètes côté serveur (Agent) et côté client (Host). Cet exemple présente un agent de chat intelligent avec des capacités de recherche web et de requête météo.
Vue d'ensemble de l'architecture
sequenceDiagram
participant User as Utilisateur
participant Client as BeeAI Chat Client
participant Server as BeeAI Chat Agent
participant LLM as Ollama (granite3.3:8b)
participant Tools as Collection d'outils
User->>Client: Saisie du message de chat
Client->>Server: Requête HTTP (Protocole A2A)
Server->>LLM: Traitement de la requête utilisateur
LLM->>Tools: Appel d'outils (recherche/météo etc.)
Tools-->>LLM: Retour des résultats d'outils
LLM-->>Server: Génération de la réponse
Server-->>Client: Retour de la réponse A2A
Client-->>User: Affichage des résultats du chat
Structure du projet
samples/python/
├── agents/beeai-chat/ # Serveur A2A (Agent)
│ ├── __main__.py # Programme principal du serveur
│ ├── pyproject.toml # Configuration des dépendances
│ ├── Dockerfile # Configuration de conteneurisation
│ └── README.md # Documentation du serveur
└── hosts/beeai-chat/ # Client A2A (Host)
├── __main__.py # Programme principal du client
├── console_reader.py # Interface d'interaction console
├── pyproject.toml # Configuration des dépendances
├── Dockerfile # Configuration de conteneurisation
└── README.md # Documentation du client
Configuration de l'environnement
Exigences système
Installation d'uv
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Ou utiliser pip
pip install uv
Installation d'Ollama et du modèle
# Installer Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Télécharger le modèle requis
ollama pull granite3.3:8b
Implémentation du serveur A2A (Agent)
Analyse de l'implémentation principale
Le serveur utilise RequirementAgent et A2AServer du framework BeeAI pour fournir des services d'agent intelligent :
def main() -> None:
# Configuration du modèle LLM
llm = ChatModel.from_name(os.environ.get("BEEAI_MODEL", "ollama:granite3.3:8b"))
# Création de l'agent avec configuration des outils
agent = RequirementAgent(
llm=llm,
tools=[ThinkTool(), DuckDuckGoSearchTool(), OpenMeteoTool(), WikipediaTool()],
memory=UnconstrainedMemory(),
)
# Démarrage du serveur A2A
A2AServer(
config=A2AServerConfig(port=int(os.environ.get("A2A_PORT", 9999))),
memory_manager=LRUMemoryManager(maxsize=100)
).register(agent).serve()
Fonctionnalités clés
- Intégration d'outils : Support de la réflexion, recherche web, requêtes météo, requêtes Wikipedia
- Gestion de la mémoire : Utilise le cache LRU pour gérer l'état des sessions
- Configuration d'environnement : Support de la configuration du modèle et du port via les variables d'environnement
Exécution du serveur avec uv
git clone https://github.com/a2aproject/a2a-samples.git
# Entrer dans le répertoire du serveur
cd samples/python/agents/beeai-chat
# Créer un environnement virtuel et installer les dépendances avec uv
uv venv
source .venv/bin/activate # Linux/macOS
uv pip install -e .
# Note importante
uv add "a2a-sdk[http-server]"
# Démarrer le serveur
uv run python __main__.py
Configuration des variables d'environnement
export BEEAI_MODEL="ollama:granite3.3:8b" # Modèle LLM
export A2A_PORT="9999" # Port du serveur
export OLLAMA_API_BASE="http://localhost:11434" # Adresse de l'API Ollama
Implémentation du client A2A (Host)
Analyse de l'implémentation principale
Le client utilise A2AAgent pour communiquer avec le serveur, fournissant une interface console interactive :
async def main() -> None:
reader = ConsoleReader()
# Création du client A2A
agent = A2AAgent(
url=os.environ.get("BEEAI_AGENT_URL", "http://127.0.0.1:9999"),
memory=UnconstrainedMemory()
)
# Boucle de traitement des entrées utilisateur
for prompt in reader:
response = await agent.run(prompt).on(
"update",
lambda data, _: (reader.write("Agent 🤖 (debug) : ", data)),
)
reader.write("Agent 🤖 : ", response.result.text)
Fonctionnalités de l'interface interactive
- Débogage en temps réel : Affiche les informations de débogage pendant le traitement de l'agent
- Sortie élégante : Saisir 'q' pour quitter le programme
- Gestion d'erreurs : Gère les entrées vides et les exceptions réseau
Exécution du client avec uv
# Entrer dans le répertoire du client
cd samples/python/hosts/beeai-chat
# Créer un environnement virtuel et installer les dépendances avec uv
uv venv
source .venv/bin/activate # Linux/macOS
uv pip install -e .
# Démarrer le client
uv run python __main__.py
Configuration des variables d'environnement
export BEEAI_AGENT_URL="http://127.0.0.1:9999" # Adresse du serveur
Flux d'exécution complet
1. Démarrer le serveur
# Terminal 1 : Démarrer le serveur A2A
cd samples/python/agents/beeai-chat
uv venv && source .venv/bin/activate
uv pip install -e .
uv add "a2a-sdk[http-server]"
uv run python __main__.py
# Sortie
INFO: Started server process [73108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9999 (Press CTRL+C to quit)
2. Démarrer le client
# Terminal 2 : Démarrer le client A2A
cd samples/python/hosts/beeai-chat
uv venv && source .venv/bin/activate
uv pip install -e .
uv run python __main__.py
# Sortie
Interactive session has started. To escape, input 'q' and submit.
User 👤 : what is the weather of new york today
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': False, 'kind': 'status-update', 'status': {'state': 'submitted', 'timestamp': '2025-09-02T07:52:09.588387+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': False, 'kind': 'status-update', 'status': {'state': 'working', 'timestamp': '2025-09-02T07:52:09.588564+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': True, 'kind': 'status-update', 'status': {'message': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'kind': 'message', 'messageId': '8dca470e-1665-41af-b0cf-6b47a1488f89', 'parts': [{'kind': 'text', 'text': 'The current weather in New York today is partly cloudy with a temperature of 16.2°C, 82% humidity, and a wind speed of 7 km/h.'}], 'role': 'agent', 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}, 'state': 'completed', 'timestamp': '2025-09-02T07:52:39.928963+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 : The current weather in New York today is partly cloudy with a temperature of 16.2°C, 82% humidity, and a wind speed of 7 km/h.
User 👤 :
3. Exemple d'interaction
Interactive session has started. To escape, input 'q' and submit.
User 👤 : Quel temps fait-il à Paris aujourd'hui ?
Agent 🤖 (debug) : Interrogation des informations météo de Paris...
Agent 🤖 : Selon les dernières données météo, Paris est nuageux aujourd'hui avec des températures de 15-22°C, 65% d'humidité et une vitesse de vent de 3m/s.
User 👤 : Rechercher les derniers développements en intelligence artificielle
Agent 🤖 (debug) : Recherche d'informations liées à l'IA...
Agent 🤖 : Selon les résultats de recherche, les récents développements majeurs en IA incluent...
User 👤 : q
Points techniques
Gestion des dépendances
Les deux projets utilisent pyproject.toml pour gérer les dépendances :
Dépendances du serveur :
dependencies = [
"beeai-framework[a2a,search] (>=0.1.36,<0.2.0)"
]
Dépendances du client :
dependencies = [
"beeai-framework[a2a] (>=0.1.36,<0.2.0)",
"pydantic (>=2.10,<3.0.0)",
]
Gestion de la mémoire
- Le serveur utilise
LRUMemoryManagerpour limiter le nombre de sessions - Le client et le serveur utilisent tous deux
UnconstrainedMemorypour maintenir l'historique des conversations
Intégration d'outils
Le serveur intègre plusieurs outils :
ThinkTool: Réflexion et raisonnement internesDuckDuckGoSearchTool: Recherche webOpenMeteoTool: Requêtes météoWikipediaTool: Requêtes Wikipedia
Extension et personnalisation
Ajout de nouveaux outils
from beeai_framework.tools.custom import CustomTool
agent = RequirementAgent(
llm=llm,
tools=[
ThinkTool(),
DuckDuckGoSearchTool(),
OpenMeteoTool(),
WikipediaTool(),
CustomTool() # Ajouter un outil personnalisé
],
memory=UnconstrainedMemory(),
)
Interface client personnalisée
Vous pouvez remplacer ConsoleReader pour implémenter une interface GUI ou Web :
class WebInterface:
async def get_user_input(self):
# Implémenter l'entrée de l'interface web
pass
async def display_response(self, response):
# Implémenter la sortie de l'interface web
pass
Résumé
Ce guide d'implémentation démontre comment construire un système de communication A2A complet en utilisant le framework BeeAI et le gestionnaire de paquets uv. Grâce à l'agent intelligent du serveur et à l'interface interactive du client, nous avons implémenté un système de chatbot riche en fonctionnalités. Cette architecture a une bonne évolutivité et peut facilement ajouter de nouveaux outils et fonctionnalités.
Plus d'exemples A2A Protocol
- A2A Multi-Agent Example: Number Guessing Game
- A2A MCP AG2 Intelligent Agent Example
- A2A + CrewAI + OpenRouter Chart Generation Agent Tutorial
- A2A JS Sample: Movie Agent
- A2A Python Sample: Github Agent
- A2A Sample: Travel Planner OpenRouter
- A2A Java Sample
- A2A Samples: Hello World Agent
- A2A Sample Methods and JSON Responses
- LlamaIndex File Chat Workflow with A2A Protocol
Featured Products
Tools and services from the A2A ecosystem directory.
View and download any TikTok user's stories and videos anonymously with SneakStory. Free, no login required, no watermark. Just paste a username to watch.


Related Articles
Explore more content related to this topic
Integrating A2A Protocol - Intelligent Agent Communication Solution for BeeAI Framework
Using A2A protocol instead of ACP is a better choice for BeeAI, reducing protocol fragmentation and improving ecosystem integration.
A2UI Introduction - Declarative UI Protocol for Agent-Driven Interfaces
Discover A2UI, the declarative UI protocol that enables AI agents to generate rich, interactive user interfaces. Learn how A2UI works, who it's for, how to use it, and see real-world examples from Google Opal, Gemini Enterprise, and Flutter GenUI SDK.
Agent Gateway Protocol (AGP): Practical Tutorial and Specification
Learn the Agent Gateway Protocol (AGP): what it is, problems it solves, core spec (capability announcements, intent payloads, routing and error codes), routing algorithm, and how to run a working simulation.
A2A vs ACP Protocol Comparison Analysis Report
A2A (Agent2Agent Protocol) and ACP (Agent Communication Protocol) represent two mainstream technical approaches in AI multi-agent system communication: 'cross-platform interoperability' and 'local/edge autonomy' respectively. A2A, with its powerful cross-vendor interconnection capabilities and rich task collaboration mechanisms, has become the preferred choice for cloud-based and distributed multi-agent scenarios; while ACP, with its low-latency, local-first, cloud-independent characteristics, is suitable for privacy-sensitive, bandwidth-constrained, or edge computing environments. Both protocols have their own focus in protocol design, ecosystem construction, and standardization governance, and are expected to further converge in openness in the future. Developers are advised to choose the most suitable protocol stack based on actual business needs.
Building an A2A Currency Agent with LangGraph
This guide provides a detailed explanation of how to build an A2A-compliant agent using LangGraph and the Google Gemini model. We'll walk through the Currency Agent example from the A2A Python SDK, explaining each component, the flow of data, and how the A2A protocol facilitates agent interactions.