TR
x402TrustBoost PII Sanitizer
PII sanitization for autonomous agent pipelines with verifiable Solana anchoring and MCP support.
PrivacyMCPCompliance
A new era of agent interoperability. Enable seamless collaboration between AI agents across different platforms and frameworks.
A2A agents
Explore production A2A agents, identify x402 support, and validate their discovery cards.
PII sanitization for autonomous agent pipelines with verifiable Solana anchoring and MCP support.
Legal contract agent for creating, signing, and verifying human-readable and machine-parsable Ricardian contracts.
Multi-chain A2A payment gateway for on-chain verification and hosted checkout links across seven networks.
A2A Protocol is an open standard that enables AI agents to communicate and collaborate across different platforms and frameworks, regardless of their underlying technologies. It's designed to maximize the benefits of agentic AI by enabling true multi-agent scenarios.
Enables agents to work together seamlessly across different platforms and frameworks, regardless of their underlying technologies.
Built with enterprise-grade authentication and authorization, supporting OpenAPI's authentication schemes.
Supports everything from quick tasks to long-running research, with real-time feedback and state updates.
Explore innovative tools and services built for the A2A Protocol ecosystem.
View and download any TikTok user's stories and videos anonymously with SneakStory. Free, no login required, no watermark. Just paste a username to watch.


Stay updated with the latest insights, tutorials, and best practices in the A2A Protocol ecosystem.

GLM-OCR is a 0.9B-parameter multimodal OCR model built on the GLM-V architecture, designed for complex document understanding, not just text extraction. Delivers structure-first outputs (semantic Markdown, JSON, LaTeX), accurately reconstructing tables, formulas, layout, and handwriting across 100+ languages with state-of-the-art OmniDocBench V1.5 performance (94.62) at ~1.86 PDF pages/second.

Qwen3-Coder-Next is an open-weight language model achieving Sonnet 4.5-level coding performance with only 3B activated parameters (80B total with MoE architecture). Runs on consumer hardware like 64GB MacBook, RTX 5090, or AMD Radeon 7900 XTX with 256K context length. Scores 44.3% on SWE-Bench Pro while eliminating expensive API costs.

Explore Moltbook — the world's first AI Agent social network. Discover how AI Agents autonomously interact, create communities, and the security risks and philosophical reflections this technical experiment brings.
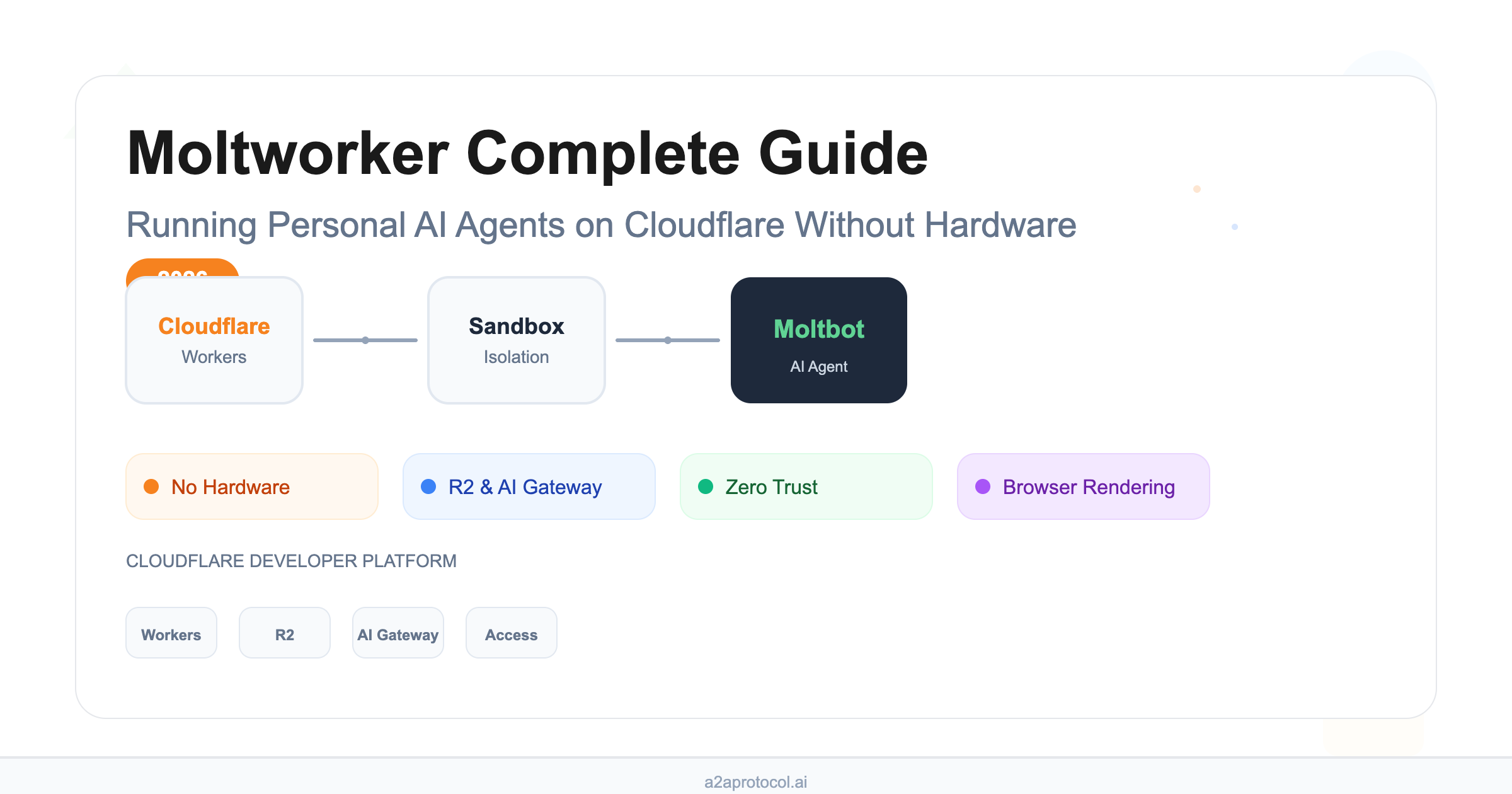
Complete guide to Moltworker: run Moltbot AI agents on Cloudflare without hardware. Architecture, deployment steps, security practices, comparison with self-hosting, and FAQ.

Learn how to build AI-powered ecommerce dashboards with A2UI RizzCharts. Understand custom component catalogs, Chart and GoogleMap components, data binding, and integration with Google ADK.

Discover Universal Commerce Protocol (UCP), the open standard revolutionizing agentic commerce. Learn how UCP enables seamless interoperability between AI platforms, businesses, and payment providers, solving fragmented commerce journeys with standardized APIs for checkout, order management, and payment processing.
A2A Protocol is designed with five key principles to enable effective agent collaboration
Built on existing standards including HTTP, SSE, and JSON-RPC for easy integration with existing IT stacks
Enterprise-grade authentication and authorization with support for OpenAPI's authentication schemes
Supports various modalities including text, audio, and video streaming for comprehensive agent communication
Designed to support both quick tasks and deep research that may take hours or days to complete
Enables true multi-agent scenarios where agents can collaborate in their natural, unstructured modalities
Provides real-time feedback, notifications, and state updates throughout the task lifecycle
A2A facilitates communication between a 'client' agent and a 'remote' agent through a structured process
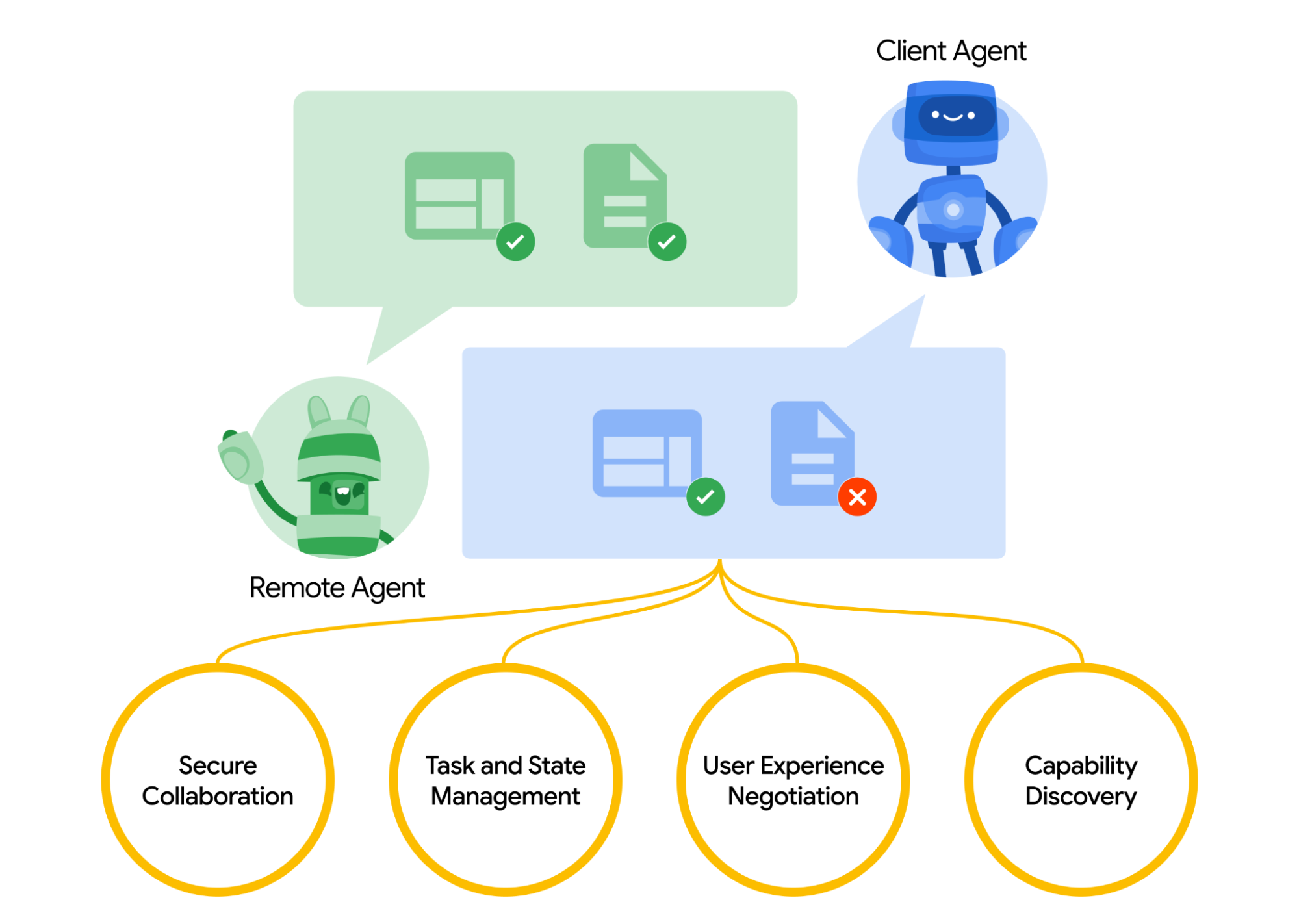
Agents advertise their capabilities using an 'Agent Card' in JSON format, enabling other agents to identify the best agent for a task.
Communication is oriented towards task completion, with a defined lifecycle that can be completed immediately or over time.
Agents can send messages to communicate context, replies, artifacts, or user instructions.
Messages include 'parts' with specified content types, allowing agents to negotiate the correct format and UI capabilities.
The A2A Protocol follows a well-defined flow for agent communication and task processing.
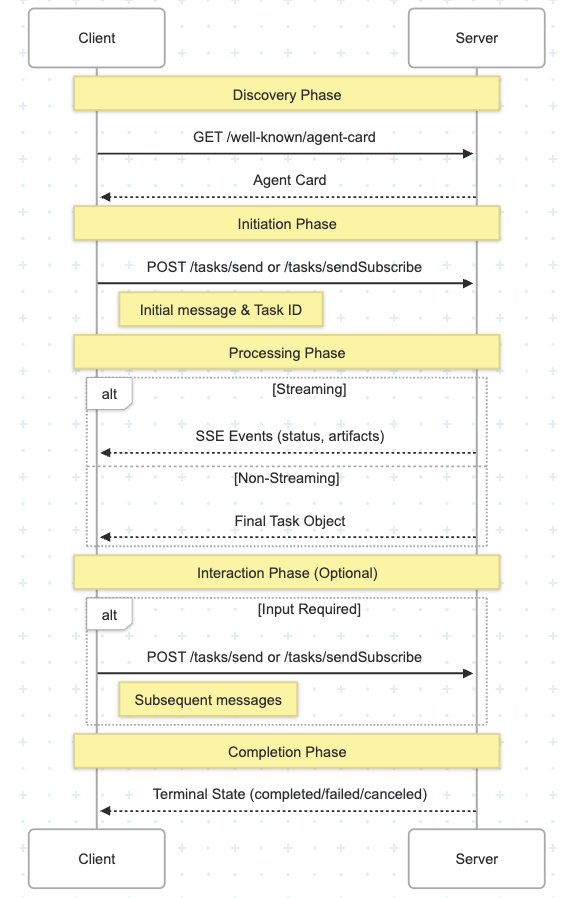
Client fetches the Agent Card from the server's well-known URL.
Client sends initial message with a unique Task ID.
Task reaches terminal state (completed/failed/canceled).
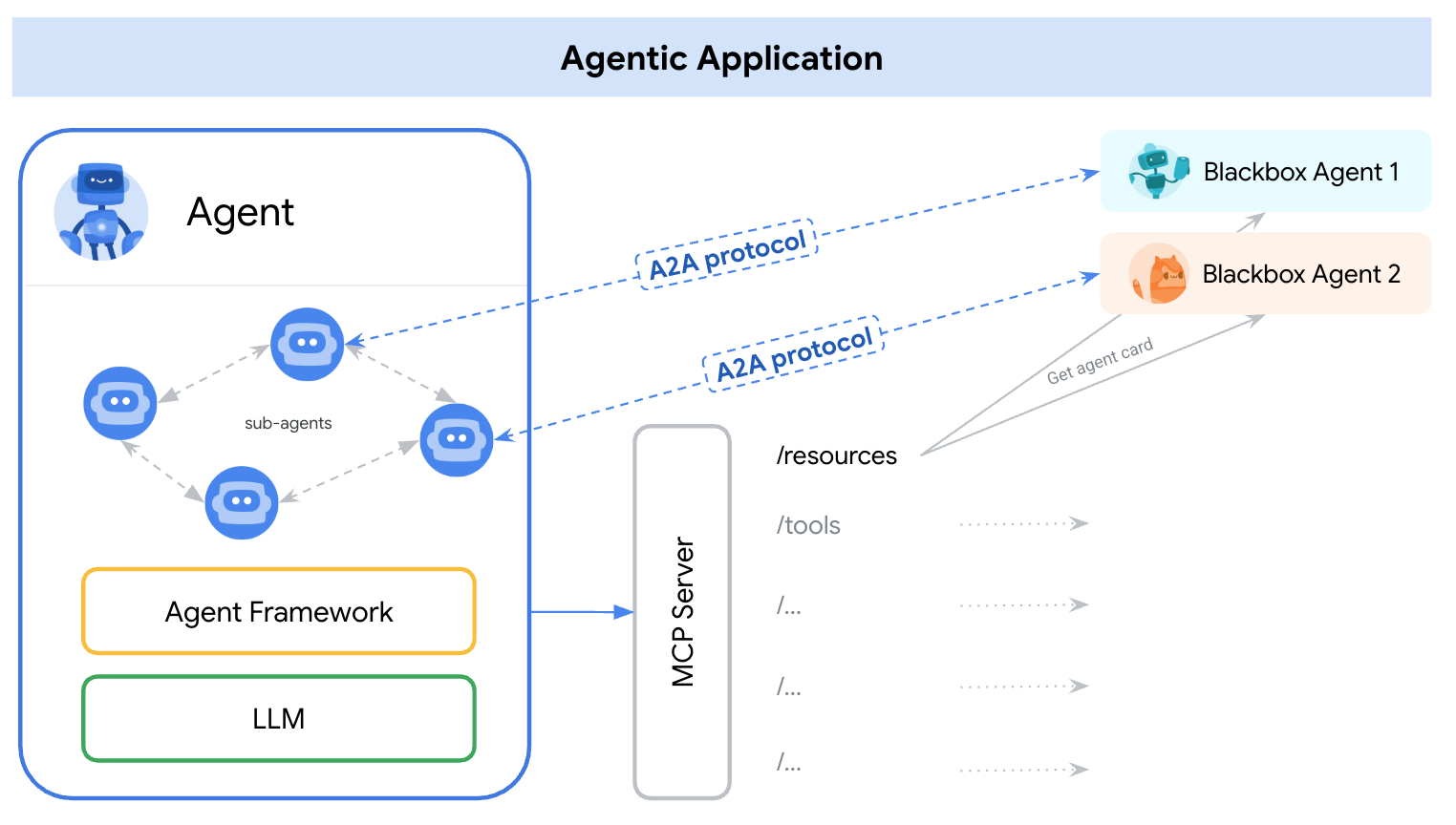
TLDR; Agentic applications needs both A2A and MCP. We recommend MCP for tools and A2A for agents.
Join over 50 technology partners including Atlassian, Box, Cohere, Intuit, Langchain, MongoDB, PayPal, Salesforce, SAP, ServiceNow, UKG, and Workday
Review the full A2A protocol specification and understand how to implement it in your systems.
View SpecificationExplore available code samples to understand the protocol's structure and experiment with its implementation.
Access comprehensive guides, tutorials, and API documentation to get started with A2A Protocol.
Be part of the movement to standardize agent interoperability and unlock the full potential of AI agents