BeeAI Framework-basierte A2A Service Implementierungsdokumentation
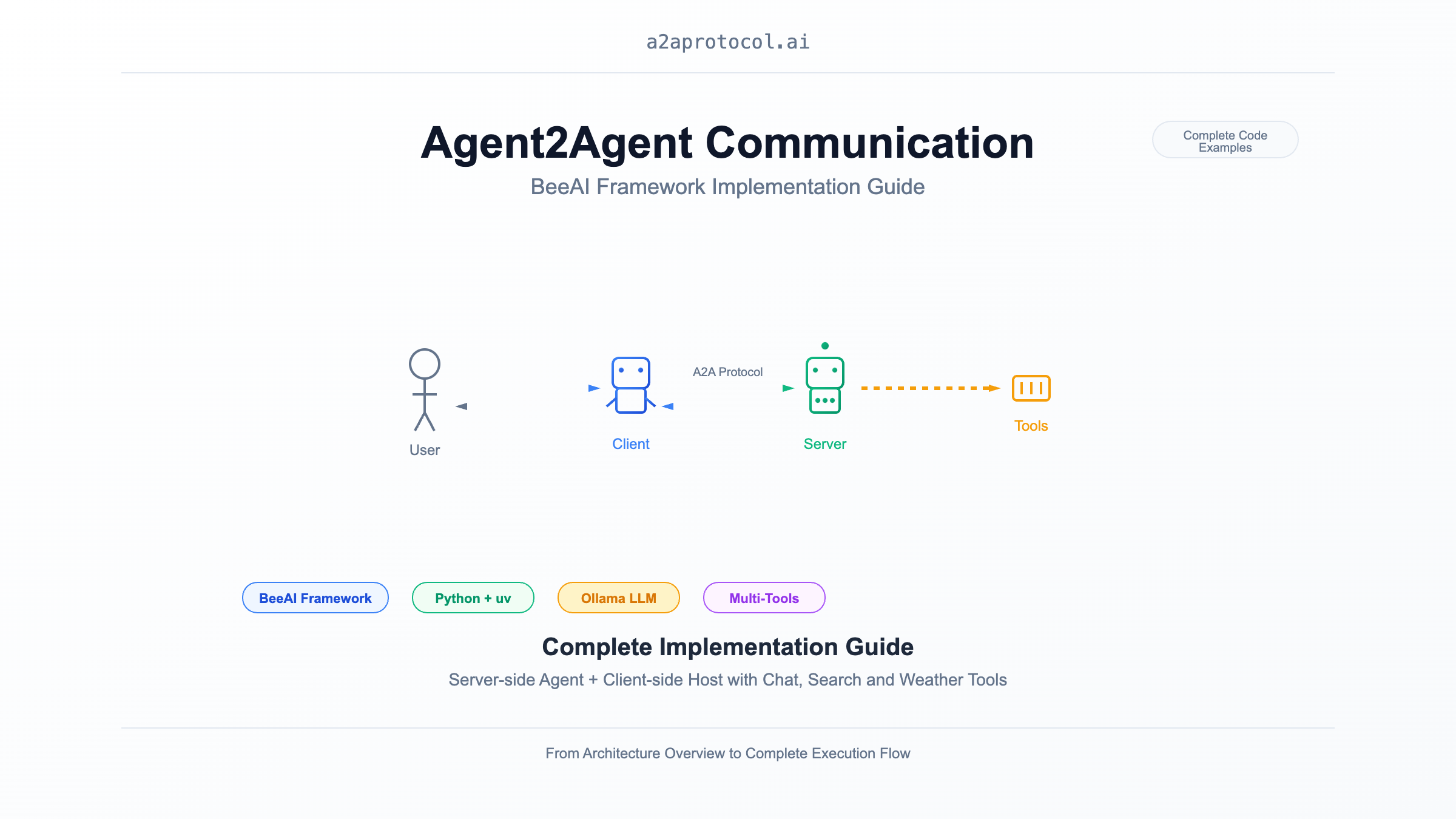
Überblick
Dieses Dokument demonstriert, wie man Agent2Agent (A2A) Kommunikation mit dem BeeAI Framework implementiert, einschließlich vollständiger Implementierungen sowohl serverseitig (Agent) als auch clientseitig (Host). Dieses Beispiel zeigt einen intelligenten Chat-Agenten mit Web-Such- und Wetterabfrage-Funktionen.
Architektur-Überblick
sequenceDiagram
participant User as Benutzer
participant Client as BeeAI Chat Client
participant Server as BeeAI Chat Agent
participant LLM as Ollama (granite3.3:8b)
participant Tools as Tool-Sammlung
User->>Client: Chat-Nachricht eingeben
Client->>Server: HTTP-Anfrage (A2A Protocol)
Server->>LLM: Benutzeranfrage verarbeiten
LLM->>Tools: Tools aufrufen (Suche/Wetter etc.)
Tools-->>LLM: Tool-Ergebnisse zurückgeben
LLM-->>Server: Antwort generieren
Server-->>Client: A2A-Antwort zurückgeben
Client-->>User: Chat-Ergebnisse anzeigen
Projektstruktur
samples/python/
├── agents/beeai-chat/ # A2A Server (Agent)
│ ├── __main__.py # Server-Hauptprogramm
│ ├── pyproject.toml # Abhängigkeitskonfiguration
│ ├── Dockerfile # Containerisierungskonfiguration
│ └── README.md # Server-Dokumentation
└── hosts/beeai-chat/ # A2A Client (Host)
├── __main__.py # Client-Hauptprogramm
├── console_reader.py # Konsolen-Interaktionsschnittstelle
├── pyproject.toml # Abhängigkeitskonfiguration
├── Dockerfile # Containerisierungskonfiguration
└── README.md # Client-Dokumentation
Umgebungseinrichtung
Systemanforderungen
uv installieren
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Oder pip verwenden
pip install uv
Ollama und Modell installieren
# Ollama installieren
curl -fsSL https://ollama.com/install.sh | sh
# Erforderliches Modell herunterladen
ollama pull granite3.3:8b
A2A Server-Implementierung (Agent)
Kern-Implementierungsanalyse
Der Server verwendet RequirementAgent und A2AServer des BeeAI Frameworks, um intelligente Agent-Services bereitzustellen:
def main() -> None:
# LLM-Modell konfigurieren
llm = ChatModel.from_name(os.environ.get("BEEAI_MODEL", "ollama:granite3.3:8b"))
# Agent mit Tool-Konfiguration erstellen
agent = RequirementAgent(
llm=llm,
tools=[ThinkTool(), DuckDuckGoSearchTool(), OpenMeteoTool(), WikipediaTool()],
memory=UnconstrainedMemory(),
)
# A2A-Server starten
A2AServer(
config=A2AServerConfig(port=int(os.environ.get("A2A_PORT", 9999))),
memory_manager=LRUMemoryManager(maxsize=100)
).register(agent).serve()
Hauptfunktionen
- Tool-Integration: Unterstützt Denken, Web-Suche, Wetterabfragen, Wikipedia-Abfragen
- Speicherverwaltung: Verwendet LRU-Cache zur Verwaltung des Sitzungsstatus
- Umgebungskonfiguration: Unterstützt Modell- und Port-Konfiguration über Umgebungsvariablen
Server mit uv ausführen
git clone https://github.com/a2aproject/a2a-samples.git
# In Server-Verzeichnis wechseln
cd samples/python/agents/beeai-chat
# Virtuelle Umgebung erstellen und Abhängigkeiten mit uv installieren
uv venv
source .venv/bin/activate # Linux/macOS
uv pip install -e .
# Wichtiger Hinweis
uv add "a2a-sdk[http-server]"
# Server starten
uv run python __main__.py
Umgebungsvariablen-Konfiguration
export BEEAI_MODEL="ollama:granite3.3:8b" # LLM-Modell
export A2A_PORT="9999" # Server-Port
export OLLAMA_API_BASE="http://localhost:11434" # Ollama API-Adresse
A2A Client-Implementierung (Host)
Kern-Implementierungsanalyse
Der Client verwendet A2AAgent zur Kommunikation mit dem Server und bietet eine interaktive Konsolen-Schnittstelle:
async def main() -> None:
reader = ConsoleReader()
# A2A-Client erstellen
agent = A2AAgent(
url=os.environ.get("BEEAI_AGENT_URL", "http://127.0.0.1:9999"),
memory=UnconstrainedMemory()
)
# Benutzereingabe-Verarbeitungsschleife
for prompt in reader:
response = await agent.run(prompt).on(
"update",
lambda data, _: (reader.write("Agent 🤖 (debug) : ", data)),
)
reader.write("Agent 🤖 : ", response.result.text)
Interaktive Schnittstellen-Funktionen
- Echtzeit-Debugging: Zeigt Debug-Informationen während der Agent-Verarbeitung an
- Eleganter Ausstieg: 'q' eingeben, um das Programm zu beenden
- Fehlerbehandlung: Behandelt leere Eingaben und Netzwerkausnahmen
Client mit uv ausführen
# In Client-Verzeichnis wechseln
cd samples/python/hosts/beeai-chat
# Virtuelle Umgebung erstellen und Abhängigkeiten mit uv installieren
uv venv
source .venv/bin/activate # Linux/macOS
uv pip install -e .
# Client starten
uv run python __main__.py
Umgebungsvariablen-Konfiguration
export BEEAI_AGENT_URL="http://127.0.0.1:9999" # Server-Adresse
Vollständiger Ausführungsablauf
1. Server starten
# Terminal 1: A2A-Server starten
cd samples/python/agents/beeai-chat
uv venv && source .venv/bin/activate
uv pip install -e .
uv add "a2a-sdk[http-server]"
uv run python __main__.py
# Ausgabe
INFO: Started server process [73108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9999 (Press CTRL+C to quit)
2. Client starten
# Terminal 2: A2A-Client starten
cd samples/python/hosts/beeai-chat
uv venv && source .venv/bin/activate
uv pip install -e .
uv run python __main__.py
# Ausgabe
Interactive session has started. To escape, input 'q' and submit.
User 👤 : what is the weather of new york today
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': False, 'kind': 'status-update', 'status': {'state': 'submitted', 'timestamp': '2025-09-02T07:52:09.588387+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': False, 'kind': 'status-update', 'status': {'state': 'working', 'timestamp': '2025-09-02T07:52:09.588564+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 (debug) : value={'id': 'cb4059ebd3a44a2f8b428d83bbff8cac', 'jsonrpc': '2.0', 'result': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'final': True, 'kind': 'status-update', 'status': {'message': {'contextId': 'b8a8d863-4c7d-48b7-9bdd-2848abccaae3', 'kind': 'message', 'messageId': '8dca470e-1665-41af-b0cf-6b47a1488f89', 'parts': [{'kind': 'text', 'text': 'The current weather in New York today is partly cloudy with a temperature of 16.2°C, 82% humidity, and a wind speed of 7 km/h.'}], 'role': 'agent', 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}, 'state': 'completed', 'timestamp': '2025-09-02T07:52:39.928963+00:00'}, 'taskId': '6e0fce64-51f0-4ad3-b0d5-c503b41bf63a'}}
Agent 🤖 : The current weather in New York today is partly cloudy with a temperature of 16.2°C, 82% humidity, and a wind speed of 7 km/h.
User 👤 :
3. Interaktionsbeispiel
Interactive session has started. To escape, input 'q' and submit.
User 👤 : Wie ist das Wetter heute in Berlin?
Agent 🤖 (debug) : Berliner Wetterinformationen werden abgerufen...
Agent 🤖 : Laut den neuesten Wetterdaten ist Berlin heute bewölkt mit Temperaturen von 15-22°C, 65% Luftfeuchtigkeit und einer Windgeschwindigkeit von 3m/s.
User 👤 : Suche nach den neuesten Entwicklungen in der künstlichen Intelligenz
Agent 🤖 (debug) : Suche nach KI-bezogenen Informationen...
Agent 🤖 : Basierend auf den Suchergebnissen umfassen die jüngsten wichtigen Entwicklungen in der KI...
User 👤 : q
Technische Punkte
Abhängigkeitsverwaltung
Beide Projekte verwenden pyproject.toml zur Verwaltung von Abhängigkeiten:
Server-Abhängigkeiten:
dependencies = [
"beeai-framework[a2a,search] (>=0.1.36,<0.2.0)"
]
Client-Abhängigkeiten:
dependencies = [
"beeai-framework[a2a] (>=0.1.36,<0.2.0)",
"pydantic (>=2.10,<3.0.0)",
]
Speicherverwaltung
- Server verwendet
LRUMemoryManagerzur Begrenzung der Sitzungsanzahl - Sowohl Client als auch Server verwenden
UnconstrainedMemoryzur Aufrechterhaltung der Gesprächshistorie
Tool-Integration
Der Server integriert mehrere Tools:
ThinkTool: Internes Denken und SchlussfolgernDuckDuckGoSearchTool: Web-SucheOpenMeteoTool: WetterabfragenWikipediaTool: Wikipedia-Abfragen
Erweiterung und Anpassung
Neue Tools hinzufügen
from beeai_framework.tools.custom import CustomTool
agent = RequirementAgent(
llm=llm,
tools=[
ThinkTool(),
DuckDuckGoSearchTool(),
OpenMeteoTool(),
WikipediaTool(),
CustomTool() # Benutzerdefiniertes Tool hinzufügen
],
memory=UnconstrainedMemory(),
)
Benutzerdefinierte Client-Schnittstelle
Sie können ConsoleReader ersetzen, um GUI- oder Web-Schnittstellen zu implementieren:
class WebInterface:
async def get_user_input(self):
# Web-Schnittstellen-Eingabe implementieren
pass
async def display_response(self, response):
# Web-Schnittstellen-Ausgabe implementieren
pass
Zusammenfassung
Diese Implementierungsdokumentation zeigt, wie man ein vollständiges A2A Kommunikationssystem mit dem BeeAI Framework und dem uv-Paketmanager aufbaut. Durch den intelligenten Agenten des Servers und die interaktive Schnittstelle des Clients haben wir ein funktionsreiches Chatbot-System implementiert. Diese Architektur hat gute Skalierbarkeit und kann leicht neue Tools und Funktionen hinzufügen.
Weitere A2A Protocol Beispiele
- A2A Multi-Agent Example: Number Guessing Game
- A2A MCP AG2 Intelligent Agent Example
- A2A + CrewAI + OpenRouter Chart Generation Agent Tutorial
- A2A JS Sample: Movie Agent
- A2A Python Sample: Github Agent
- A2A Sample: Travel Planner OpenRouter
- A2A Java Sample
- A2A Samples: Hello World Agent
- A2A Sample Methods and JSON Responses
- LlamaIndex File Chat Workflow with A2A Protocol
Featured Products
Tools and services from the A2A ecosystem directory.
View and download any TikTok user's stories and videos anonymously with SneakStory. Free, no login required, no watermark. Just paste a username to watch.


Related Articles
Explore more content related to this topic
Integrating A2A Protocol - Intelligent Agent Communication Solution for BeeAI Framework
Using A2A protocol instead of ACP is a better choice for BeeAI, reducing protocol fragmentation and improving ecosystem integration.
A2UI Introduction - Declarative UI Protocol for Agent-Driven Interfaces
Discover A2UI, the declarative UI protocol that enables AI agents to generate rich, interactive user interfaces. Learn how A2UI works, who it's for, how to use it, and see real-world examples from Google Opal, Gemini Enterprise, and Flutter GenUI SDK.
Agent Gateway Protocol (AGP): Practical Tutorial and Specification
Learn the Agent Gateway Protocol (AGP): what it is, problems it solves, core spec (capability announcements, intent payloads, routing and error codes), routing algorithm, and how to run a working simulation.
A2A vs ACP Protocol Comparison Analysis Report
A2A (Agent2Agent Protocol) and ACP (Agent Communication Protocol) represent two mainstream technical approaches in AI multi-agent system communication: 'cross-platform interoperability' and 'local/edge autonomy' respectively. A2A, with its powerful cross-vendor interconnection capabilities and rich task collaboration mechanisms, has become the preferred choice for cloud-based and distributed multi-agent scenarios; while ACP, with its low-latency, local-first, cloud-independent characteristics, is suitable for privacy-sensitive, bandwidth-constrained, or edge computing environments. Both protocols have their own focus in protocol design, ecosystem construction, and standardization governance, and are expected to further converge in openness in the future. Developers are advised to choose the most suitable protocol stack based on actual business needs.
Building an A2A Currency Agent with LangGraph
This guide provides a detailed explanation of how to build an A2A-compliant agent using LangGraph and the Google Gemini model. We'll walk through the Currency Agent example from the A2A Python SDK, explaining each component, the flow of data, and how the A2A protocol facilitates agent interactions.