A2A Traceability Extension: Tiefgreifende Analyse und Anwendungsleitfaden
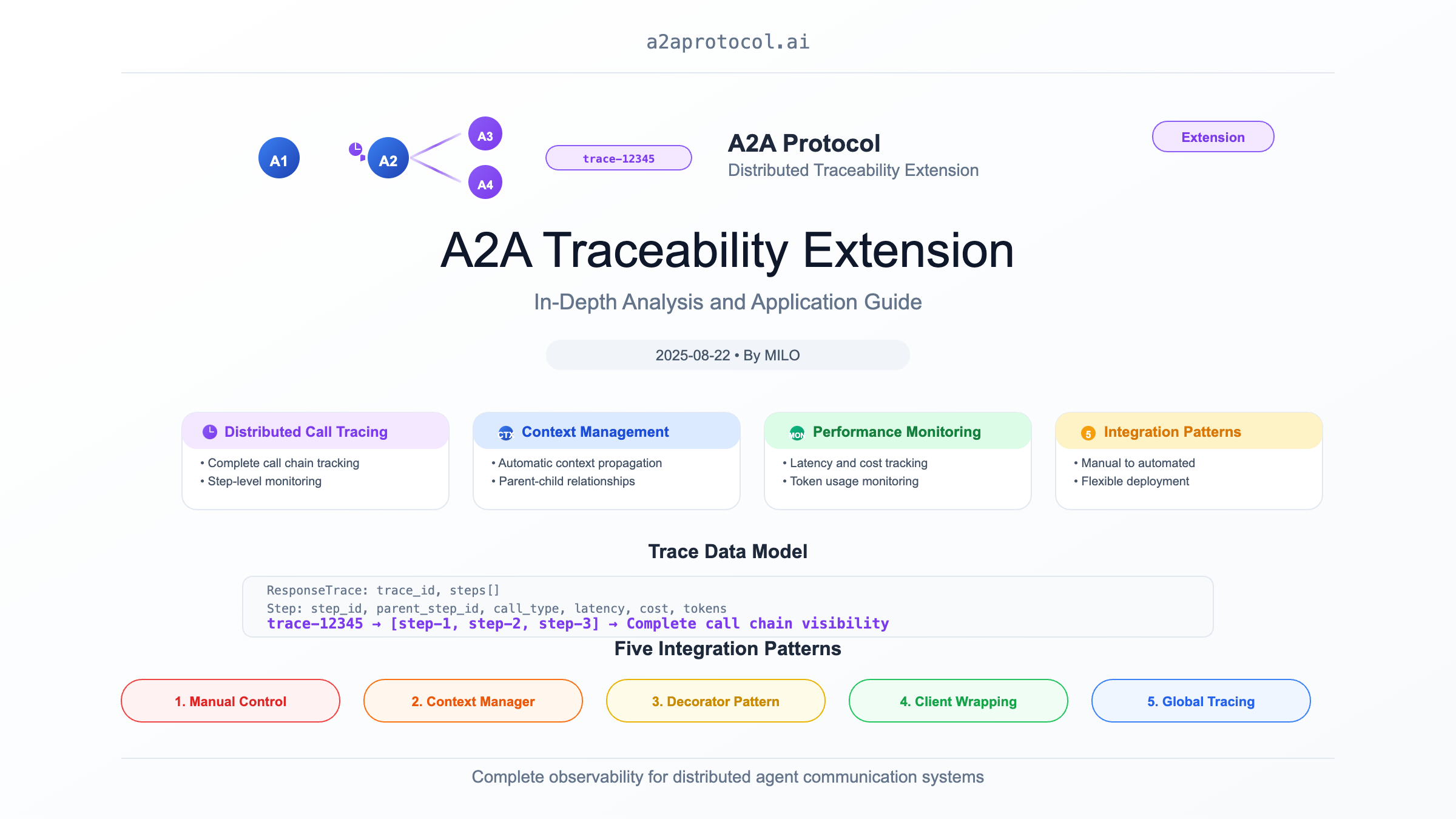
Überblick
Die A2A (Agent2Agent) Traceability Extension ist ein leistungsstarkes verteiltes Tracing-System, das speziell entwickelt wurde, um vollständiges Call-Chain-Tracing für die Agent-zu-Agent-Kommunikation im A2A-Framework zu bieten. Diese Extension implementiert Funktionalitäten ähnlich wie verteilte Tracing-Systeme (wie Jaeger, Zipkin), ist aber für die spezifischen Anforderungen von Multi-Agent-Systemen optimiert.
Kernfunktionen
1. Verteiltes Call-Tracing
- Vollständige Call-Chain: Zeichnet vollständige Call-Pfade und Abhängigkeiten zwischen Agenten auf
- Step-Level-Monitoring: Verfolgt detaillierte Informationen für jeden Operationsschritt
- Geschachteltes Tracing: Unterstützt komplexe geschachtelte Calls und rekursive Szenarien
- Performance-Monitoring: Sammelt Schlüsselmetriken wie Latenz, Kosten und Token-Verbrauch
2. Intelligentes Kontext-Management
- Automatische Kontext-Propagation: Übergibt automatisch Tracing-Kontext durch Agent-Call-Chains
- Parent-Child-Beziehungs-Wartung: Zeichnet die hierarchische Struktur von Calls präzise auf
- Fehler-Propagation: Verfolgt Fehler-Propagationspfade durch die Call-Chain
3. Vielfältige Integrationsansätze
- Kontext-Manager: Vereinfacht Tracing-Code mit
TraceStep - Decorator-Pattern: Bietet transparente Tracing-Funktionalitäts-Integration
- Manuelle Kontrolle: Vollständige Kontrolle über den Tracing-Lebenszyklus
Design-Prinzipien
Architektur-Muster
Die Extension übernimmt Kern-Design-Muster von modernen verteilten Tracing-Systemen:
-
Geschichtetes Tracing-Modell:
- Trace: Repräsentiert eine vollständige Geschäftsoperation
- Step: Individuelle Operationseinheit innerhalb einer Trace
- Kontext: Tracing-Informationen, die durch die Call-Chain übertragen werden
-
Observer-Pattern: Sammelt automatisch Tracing-Daten über Kontext-Manager
-
Strategy-Pattern: Unterstützt verschiedene Tracing-Strategien und Konfigurationen
Datenmodell
ResponseTrace
class ResponseTrace:
trace_id: str # Eindeutige Trace-Kennung
steps: List[Step] # Liste der Trace-Steps
Step
class Step:
step_id: str # Eindeutige Step-Kennung
trace_id: str # Zugehörige Trace-ID
parent_step_id: str # Parent-Step-ID
call_type: CallTypeEnum # Call-Typ (AGENT/TOOL/HOST)
start_time: datetime # Startzeit
end_time: datetime # Endzeit
latency: int # Latenz (Millisekunden)
cost: float # Operationskosten
total_tokens: int # Token-Verbrauch
error: Any # Fehlerinformationen
Gelöste Kernprobleme
1. Observability in Multi-Agent-Systemen
In komplexen Multi-Agent-Systemen kann eine Benutzeranfrage die Zusammenarbeit zwischen mehreren Agenten auslösen:
Benutzeranfrage -> Koordinator-Agent -> Daten-Agent -> Analyse-Agent -> Entscheidungs-Agent -> Ausführungs-Agent
Probleme ohne Tracing:
- Kann den vollständigen Flusspfad von Anfragen durch das System nicht verstehen
- Schwierig, Performance-Engpässe und Ausfallpunkte zu lokalisieren
- Mangel an End-to-End-Performance-Monitoring
- Unfähig, effektive Systemoptimierung durchzuführen
2. Kosten- und Performance-Monitoring für Agent-Calls
Moderne KI-Agenten beinhalten typischerweise teure LLM-Calls:
# Ohne Tracing kann man nicht beantworten:
# - Wie viel hat diese Unterhaltung insgesamt gekostet?
# - Welcher Agent hat die meisten Token verbraucht?
# - Wo sind die Performance-Engpässe?
user_query -> agent_a -> llm_call(cost=$0.05, tokens=1000)
-> agent_b -> llm_call(cost=$0.08, tokens=1500)
-> agent_c -> tool_call(latency=2000ms)
3. Fehler-Propagation und Fehlerdiagnose
Wenn ein Fehler in der Agent-Chain auftritt, ist eine schnelle Problemlokalisierung erforderlich:
# Mit Tracing können Sie klar sehen:
Trace ID: trace-12345
├── Step 1: UserQuery (success, 10ms)
├── Step 2: DataAgent (success, 200ms, $0.05)
├── Step 3: AnalysisAgent (failed, 1500ms, error: "API timeout")
└── Step 4: DecisionAgent (skipped due to upstream failure)
Technische Implementierungsdetails
1. Kontext-Manager-Pattern
class TraceStep:
"""Kontext-Manager, der automatisch den Trace-Step-Lebenszyklus verwaltet"""
def __enter__(self) -> TraceRecord:
# Tracing starten, Startzeit aufzeichnen
return self.step
def __exit__(self, exc_type, exc_val, exc_tb):
# Tracing beenden, Endzeit und Fehlerinformationen aufzeichnen
self.step.end_step(error=error_msg)
if self.response_trace:
self.response_trace.add_step(self.step)
Verwendungsbeispiel:
with TraceStep(trace, CallTypeEnum.AGENT, name="Datenabfrage") as step:
result = await data_agent.query(params)
step.end_step(cost=0.05, total_tokens=1000)
2. Automatisierte Tracing-Integration
# Transparente Integration, kein Business-Code muss geändert werden
original_client = AgentClient()
traced_client = ext.wrap_client(original_client)
# Alle Calls über traced_client werden automatisch getrackt
response = await traced_client.call_agent(request)
3. Extension-Aktivierungsmechanismus
Tracing wird über HTTP-Header aktiviert:
X-A2A-Extensions: https://github.com/a2aproject/a2a-samples/extensions/traceability/v1
Fünf Integrationsmuster
Muster 1: Vollständige manuelle Kontrolle
Entwickler haben vollständige Kontrolle über Trace-Erstellung und -Management:
ext = TraceabilityExtension()
trace = ResponseTrace()
step = TraceRecord(CallTypeEnum.AGENT, name="Benutzerabfrage")
# ... Geschäftslogik ...
step.end_step(cost=0.1, total_tokens=500)
trace.add_step(step)
Anwendungsfall: Erweiterte Szenarien, die präzise Kontrolle über Tracing-Granularität und -Inhalt erfordern
Muster 2: Kontext-Manager
Verwendet Kontext-Manager zur Vereinfachung des Tracing-Codes:
with TraceStep(trace, CallTypeEnum.TOOL, name="Datenbankabfrage") as step:
result = database.query(sql)
step.end_step(cost=0.02, additional_attributes={"rows": len(result)})
Anwendungsfall: Präzises Tracing innerhalb spezifischer Code-Blöcke
Muster 3: Decorator-Automatisierung
Implementiert transparentes Tracing über Decorators:
@trace_agent_call
async def process_request(request):
# Alle Agent-Calls werden automatisch getrackt
return await some_agent.process(request)
Anwendungsfall: Szenarien, die minimale Code-Änderungen erfordern
Real-World-Anwendungsszenarien
1. Intelligentes Kundenservice-System-Tracing
# Vollständiges Kundenservice-Verarbeitungsfluss-Tracing
with TraceStep(trace, CallTypeEnum.AGENT, "Kundenservice-Verarbeitung") as main_step:
# Intent-Erkennung
with TraceStep(trace, CallTypeEnum.AGENT, "Intent-Erkennung", parent_step_id=main_step.step_id) as intent_step:
intent = await intent_agent.classify(user_message)
intent_step.end_step(cost=0.02, total_tokens=200)
# Wissensabfrage
with TraceStep(trace, CallTypeEnum.TOOL, "Wissensabfrage", parent_step_id=main_step.step_id) as kb_step:
knowledge = await knowledge_base.search(intent)
kb_step.end_step(latency=150, additional_attributes={"results": len(knowledge)})
# Antwortgenerierung
with TraceStep(trace, CallTypeEnum.AGENT, "Antwortgenerierung", parent_step_id=main_step.step_id) as gen_step:
response = await response_agent.generate(intent, knowledge)
gen_step.end_step(cost=0.08, total_tokens=800)
main_step.end_step(cost=0.10, total_tokens=1000)
Performance-Monitoring und -Analyse
Trace-Datenanalyse
def analyze_trace_performance(trace: ResponseTrace):
"""Trace-Performance-Daten analysieren"""
total_cost = sum(step.cost or 0 for step in trace.steps)
total_tokens = sum(step.total_tokens or 0 for step in trace.steps)
total_latency = max(step.end_time for step in trace.steps) - min(step.start_time for step in trace.steps)
# Performance-Engpässe identifizieren
bottleneck = max(trace.steps, key=lambda s: s.latency or 0)
# Kostenanalyse
cost_by_type = defaultdict(float)
for step in trace.steps:
cost_by_type[step.call_type] += step.cost or 0
return {
"gesamtkosten": total_cost,
"gesamt_tokens": total_tokens,
"gesamtlatenz": total_latency.total_seconds() * 1000,
"engpass": f"{bottleneck.name} ({bottleneck.latency}ms)",
"kostenverteilung": dict(cost_by_type)
}
Best Practices
1. Angemessene Tracing-Granularität
# ✅ Gute Praxis: Kerngeschäftsoperationen
with TraceStep(trace, CallTypeEnum.AGENT, "Bestellverarbeitung"):
process_order(order)
# ❌ Vermeiden: Zu feinkörniges Tracing
with TraceStep(trace, CallTypeEnum.TOOL, "Variablenzuweisung"): # Zu granular
x = y + 1
2. Aussagekräftige Step-Benennung
# ✅ Klare Geschäftssemantik
with TraceStep(trace, CallTypeEnum.AGENT, "Benutzerauthentifizierung") as step:
# ✅ Schlüsselparameter einschließen
with TraceStep(trace, CallTypeEnum.TOOL, f"Datenbankabfrage-{table_name}") as step:
# ❌ Technische Implementierungsdetails
with TraceStep(trace, CallTypeEnum.TOOL, "SQL SELECT-Statement-Ausführung") as step:
3. Ordnungsgemäße Fehlerbehandlung
with TraceStep(trace, CallTypeEnum.AGENT, "Externe API-Call") as step:
try:
result = await external_api.call()
step.end_step(
cost=calculate_cost(result),
additional_attributes={"status": "success"}
)
except ApiException as e:
step.end_step(
error=str(e),
additional_attributes={"status": "failed", "error_code": e.code}
)
raise
4. Schutz sensibler Informationen
# ✅ Sichere Parameter-Aufzeichnung
with TraceStep(trace, CallTypeEnum.AGENT, "Benutzerauthentifizierung",
parameters={"user_id": user.id}) as step: # Nur ID aufzeichnen
# ❌ Aufzeichnung sensibler Informationen vermeiden
with TraceStep(trace, CallTypeEnum.AGENT, "Benutzerauthentifizierung",
parameters={"password": user.password}) as step: # Gefährlich!
Integration mit anderen Systemen
1. Logging-System-Integration
import logging
class TracingLogHandler(logging.Handler):
"""Tracing-Informationen in das Logging-System integrieren"""
def emit(self, record):
if hasattr(record, 'trace_id'):
record.msg = f"[trace:{record.trace_id}] {record.msg}"
super().emit(record)
2. Monitoring-System-Integration
class PrometheusTraceExporter:
"""Trace-Metriken zu Prometheus exportieren"""
def export_trace(self, trace: ResponseTrace):
# Latenz-Metriken exportieren
latency_histogram.observe(trace.total_latency)
# Kosten-Metriken exportieren
cost_gauge.set(trace.total_cost)
# Fehlerrate exportieren
if trace.has_errors:
error_counter.inc()
Zusammenfassung
Die A2A Traceability Extension bietet Enterprise-Level verteilte Tracing-Fähigkeiten für Multi-Agent-Systeme und adressiert Observability-Herausforderungen in komplexen Agent-Netzwerken. Sie bietet nicht nur technische Implementierung, sondern etabliert wichtiger noch Standardmuster für das Monitoring und die Optimierung von Multi-Agent-Systemen.
Kernwert:
- Vollständige Sichtbarkeit: Bietet End-to-End-Sichtbarkeit in Agent-Call-Chains
- Performance-Optimierung: Unterstützt Systemoptimierung durch detaillierte Performance-Daten
- Fehlerdiagnose: Lokalisiert und löst schnell Probleme in verteilten Systemen
- Kostenkontrolle: Verfolgt und optimiert präzise die Nutzungskosten von KI-Agenten
Design-Vorteile:
- Flexible Integration: Mehrere Integrationsansätze von manuell bis automatisch
- Standardisierung: Folgt Industriestandards für verteiltes Tracing
- Hohe Performance: Minimaler Performance-Impact auf Business-Code
- Erweiterbar: Unterstützt benutzerdefinierte Attribute und erweiterte Funktionalitäten
Diese Extension bietet eine solide Grundlage für den Aufbau zuverlässiger, überwachbarer und optimierbarer Multi-Agent-Systeme und dient als wichtiger Bestandteil moderner KI-System-Engineering-Praktiken.
Weitere Extensions
Featured Products
Tools and services from the A2A ecosystem directory.



HowHeight is the most powerful free visual height comparison tool for people, animals, objects, and characters, with charts in cm and ft + in.

Turn complex PDFs into clean Markdown that people can review and AI tools can use.
Create powerful Discord bots with AI. The easiest no-code bot maker for moderation, music, leveling, and custom commands.
Related Articles
Explore more content related to this topic
Agent Gateway Protocol (AGP): Practical Tutorial and Specification
Learn the Agent Gateway Protocol (AGP): what it is, problems it solves, core spec (capability announcements, intent payloads, routing and error codes), routing algorithm, and how to run a working simulation.
A2A Protocol Extension: Secure Passport Complete Guide
The Secure Passport Extension introduces a trusted context layer to the Agent2Agent (A2A) protocol, enabling calling agents to securely and voluntarily share a structured subset of their current context state with called agents. This extension aims to transform anonymous, transactional calls into collaborative partnerships.
A2A Timestamp Extension: In-Depth Analysis and Application Guide
A2A timestamp extension analysis and application guide
A2UI Introduction - Declarative UI Protocol for Agent-Driven Interfaces
Discover A2UI, the declarative UI protocol that enables AI agents to generate rich, interactive user interfaces. Learn how A2UI works, who it's for, how to use it, and see real-world examples from Google Opal, Gemini Enterprise, and Flutter GenUI SDK.
Integrating A2A Protocol - Intelligent Agent Communication Solution for BeeAI Framework
Using A2A protocol instead of ACP is a better choice for BeeAI, reducing protocol fragmentation and improving ecosystem integration.