Échantillons A2A : Agent de Chat de Fichiers LlamaIndex
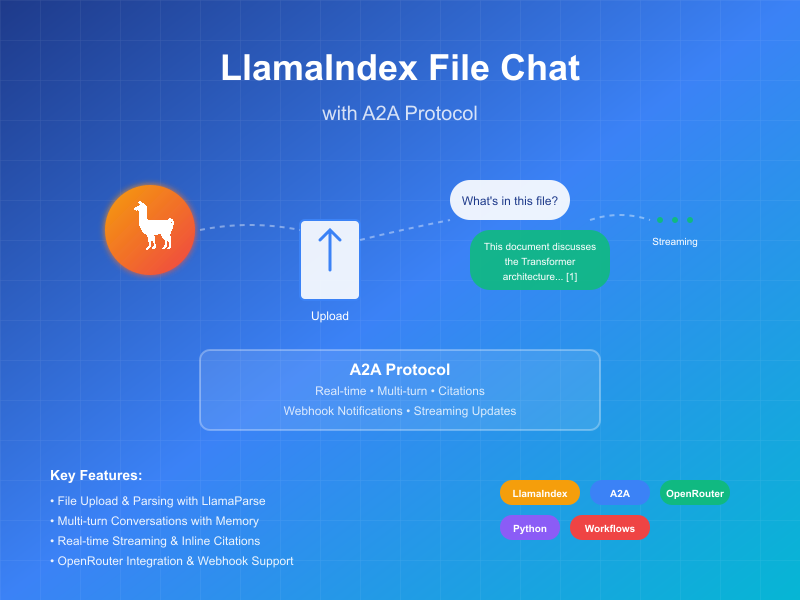
Cet échantillon démontre un agent conversationnel construit avec LlamaIndex Workflows et exposé via le protocole A2A. Il présente le téléchargement et l'analyse de fichiers, les interactions conversationnelles avec support pour le dialogue multi-tours, les réponses/mises à jour en streaming, et les citations en ligne.
code source
a2a llama index file chat avec openrouter
Comment ça fonctionne
Cet agent utilise LlamaIndex Workflows avec OpenRouter pour fournir un agent conversationnel qui peut télécharger des fichiers, les analyser, et répondre aux questions sur le contenu. Le protocole A2A permet une interaction standardisée avec l'agent, permettant aux clients d'envoyer des requêtes et de recevoir des mises à jour en temps réel.
sequenceDiagram
participant Client as Client A2A
participant Server as Serveur A2A
participant Workflow as Flux ParseAndChat
participant Services as APIs Externes
Client->>Server: Envoyer message (avec ou sans pièce jointe)
Server->>Workflow: Transférer comme InputEvent
alt A une pièce jointe
Workflow-->>Server: Stream LogEvent "Analyse du document..."
Server-->>Client: Mise à jour du statut en streaming
Workflow->>Services: Analyser le document
Workflow-->>Server: Stream LogEvent "Document analysé avec succès"
Server-->>Client: Mise à jour du statut en streaming
end
Workflow-->>Server: Stream LogEvent sur le traitement du chat
Server-->>Client: Mise à jour du statut en streaming
Workflow->>Services: Chat LLM (avec contexte du document si disponible)
Services->>Workflow: Réponse LLM structurée
Workflow-->>Server: Stream LogEvent sur le traitement de la réponse
Server-->>Client: Mise à jour du statut en streaming
Workflow->>Server: Retourner ChatResponseEvent final
Server->>Client: Retourner réponse avec citations (si disponibles)
Note over Server: Le contexte est maintenu pour les questions de suivi
Fonctionnalités clés
- Téléchargement de fichiers : Les clients peuvent télécharger des fichiers et les analyser pour fournir un contexte au chat
- Conversations multi-tours : L'agent peut demander des informations supplémentaires quand nécessaire
- Streaming en temps réel : Fournit des mises à jour de statut pendant le traitement
- Notifications push : Support pour les notifications basées sur webhook
- Mémoire conversationnelle : Maintient le contexte à travers les interactions dans la même session
- Intégration LlamaParse : Utilise LlamaParse pour analyser les fichiers avec précision
NOTE : Cet agent échantillon accepte les entrées multimodales, mais au moment de l'écriture, l'interface utilisateur échantillon ne supporte que les entrées texte. L'interface utilisateur deviendra multimodale à l'avenir pour gérer ce cas d'usage et d'autres.
Prérequis
- Python 3.12 ou supérieur
- UV
- Accès à un LLM et une clé API (Le code actuel suppose l'utilisation de l'API OpenRouter)
- Une clé API LlamaParse (obtenez-en une gratuitement)
Configuration et exécution
-
Clonez et naviguez vers le répertoire du projet :
git clone https://github.com/sing1ee/a2a_llama_index_file_chat cd a2a_llama_index_file_chat -
Créez un environnement virtuel et installez les dépendances :
uv venv uv sync -
Créez un fichier d'environnement avec vos clés API :
echo "OPENROUTER_API_KEY=votre_cle_api_ici" >> .env echo "LLAMA_CLOUD_API_KEY=votre_cle_api_ici" >> .envObtenir les clés API :
- Clé API OpenRouter : Inscrivez-vous sur https://openrouter.ai pour obtenir votre clé API gratuite
- Clé API LlamaCloud : Obtenez-en une gratuitement sur https://cloud.llamaindex.ai
-
Exécutez l'agent :
# En utilisant uv uv run a2a-file-chat # Ou activez l'environnement virtuel et exécutez directement source .venv/bin/activate # Sur Windows : .venv\Scripts\activate python -m a2a_file_chat # Avec hôte/port personnalisé uv run a2a-file-chat --host 0.0.0.0 --port 8080 -
Dans un terminal séparé, exécutez un cli client A2A :
Téléchargez un fichier à analyser, ou liez vers votre propre fichier. Par exemple :
curl -L https://arxiv.org/pdf/1706.03762 -o attention.pdf
git clone https://github.com/google-a2a/a2a-samples.git
cd a2a-samples/samples/python/hosts/cli
uv run . --agent http://localhost:10010
Et entrez quelque chose comme ce qui suit :
======= Carte Agent ========
{"name":"Parse and Chat","description":"Analyse un fichier puis discute avec un utilisateur en utilisant le contenu analysé comme contexte.","url":"http://localhost:10010/","version":"1.0.0","capabilities":{"streaming":true,"pushNotifications":true,"stateTransitionHistory":false},"defaultInputModes":["text","text/plain"],"defaultOutputModes":["text","text/plain"],"skills":[{"id":"parse_and_chat","name":"Parse and Chat","description":"Analyse un fichier puis discute avec un utilisateur en utilisant le contenu analysé comme contexte.","tags":["parse","chat","file","llama_parse"],"examples":["De quoi parle ce fichier ?"]}]}
========= démarrage d'une nouvelle tâche ========
Que voulez-vous envoyer à l'agent ? (:q ou quit pour quitter) : De quoi parle ce fichier ?
Sélectionnez un chemin de fichier à joindre ? (appuyez sur entrée pour ignorer) : ./attention.pdf
Implémentation technique
- LlamaIndex Workflows : Utilise un flux de travail personnalisé pour analyser le fichier puis discuter avec l'utilisateur
- Support de streaming : Fournit des mises à jour incrémentales pendant le traitement
- Contexte sérialisable : Maintient l'état de conversation entre les tours, peut optionnellement être persisté vers redis, mongodb, sur disque, etc.
- Système de notification push : Mises à jour basées sur webhook avec authentification JWK
- Intégration du protocole A2A : Conformité complète avec les spécifications A2A
Limitations
- Ne supporte que la sortie basée sur le texte
- LlamaParse est gratuit pour les premiers 10K crédits (~3333 pages avec les paramètres de base)
- La mémoire est basée sur la session et en mémoire, et donc pas persistée entre les redémarrages du serveur
- Insérer l'ensemble du document dans la fenêtre de contexte n'est pas évolutif pour les fichiers plus volumineux. Vous pourriez vouloir déployer une base de données vectorielle ou utiliser une base de données cloud pour exécuter la récupération sur un ou plusieurs fichiers pour un RAG efficace. LlamaIndex s'intègre avec une tonne de bases de données vectorielles et de bases de données cloud.
Exemples
Requête synchrone
Requête :
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "De quoi parle ce fichier ?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Réponse :
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "129",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "Ce fichier parle de XYZ... [1]"
}
],
"metadata": {
"1": ["Texte pour la citation 1"]
}
"index": 0,
}
],
}
}
Exemple multi-tours
Requête - Séq 1 :
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "De quoi parle ce fichier ?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Réponse - Séq 2 :
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "129",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "Ce fichier parle de XYZ... [1]"
}
],
"metadata": {
"1": ["Texte pour la citation 1"]
}
"index": 0,
}
],
}
}
Requête - Séq 3 :
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "130",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Qu'en est-il de la chose X ?"
}
]
}
}
}
Réponse - Séq 4 :
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "130",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "La chose X est ... [1]"
}
],
"metadata": {
"1": ["Texte pour la citation 1"]
}
"index": 0,
}
],
}
}
Exemple de streaming
Requête :
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "De quoi parle ce fichier ?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Réponse :
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Analyse du document..."}]},"timestamp":"2025-04-15T16:05:18.283682"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Document analysé avec succès."}]},"timestamp":"2025-04-15T16:05:24.200133"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Discussion avec 1 messages initiaux."}]},"timestamp":"2025-04-15T16:05:24.204757"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Insertion du prompt système..."}]},"timestamp":"2025-04-15T16:05:24.204810"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Réponse LLM reçue, analyse des citations..."}]},"timestamp":"2025-04-15T16:05:26.084829"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","artifact":{"parts":[{"type":"text","text":"Ce fichier discute du Transformer, une nouvelle architecture de réseau de neurones basée uniquement sur des mécanismes d'attention, se dispensant entièrement de récurrence et de convolutions [1]. Le document compare le Transformer aux couches récurrentes et convolutionnelles [2], détaille l'architecture du modèle [3], et présente les résultats des tâches de traduction automatique et d'analyse syntaxique de l'anglais [4]."}],"metadata":{"1":["Les modèles de transduction de séquence dominants sont basés sur des réseaux de neurones récurrents ou convolutionnels complexes qui incluent un encodeur et un décodeur. Les modèles les plus performants connectent également l'encodeur et le décodeur via un mécanisme d'attention. Nous proposons une nouvelle architecture de réseau simple, le Transformer, basée uniquement sur des mécanismes d'attention, se dispensant entièrement de récurrence et de convolutions. Les expériences sur deux tâches de traduction automatique montrent que ces modèles sont supérieurs en qualité tout en étant plus parallélisables et nécessitant significativement moins de temps d'entraînement. Notre modèle atteint 28,4 BLEU sur la tâche de traduction anglais-allemand WMT 2014, améliorant les meilleurs résultats existants, y compris les ensembles, de plus de 2 BLEU. Sur la tâche de traduction anglais-français WMT 2014, notre modèle établit un nouveau score BLEU état de l'art à modèle unique de 41,8 après entraînement pendant 3,5 jours sur huit GPU, une petite fraction des coûts d'entraînement des meilleurs modèles de la littérature. Nous montrons que le Transformer se généralise bien à d'autres tâches en l'appliquant avec succès à l'analyse syntaxique de l'anglais avec des données d'entraînement importantes et limitées."],"2":["Dans cette section, nous comparons divers aspects des couches d'auto-attention aux couches récurrentes et convolutionnelles couramment utilisées pour mapper une séquence de longueur variable de représentations de symboles (x1, ..., xn) à une autre séquence de longueur égale (z1, ..., zn), avec xi, zi ∈ Rd, comme une couche cachée dans un encodeur ou décodeur de transduction de séquence typique. Motivant notre utilisation de l'auto-attention, nous considérons trois desiderata.",""],"3":["# 3 Architecture du modèle"],"4":["# 6 Résultats"]},"index":0,"append":false}}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"completed","timestamp":"2025-04-15T16:05:26.111314"},"final":true}}
Vous pouvez voir que le flux de travail a produit un artefact avec des citations en ligne, et le texte source de ces citations est inclus dans les métadonnées de l'artefact. Si nous envoyons plus de réponses dans la même session, l'agent se souviendra des messages précédents et continuera la conversation.
En savoir plus
Featured Products
Tools and services from the A2A ecosystem directory.



HowHeight is the most powerful free visual height comparison tool for people, animals, objects, and characters, with charts in cm and ft + in.

Turn complex PDFs into clean Markdown that people can review and AI tools can use.
Related Articles
Explore more content related to this topic
A2A Sample: Travel Planner OpenRouter
A2A implementation of Travel Planner with OpenRouter and Python a2a-sdk
Implementing CurrencyAgent with A2A Python SDK
A step-by-step guide to building a currency conversion agent with A2A Python SDK. Features detailed implementation of CurrencyAgent, AgentExecutor, and AgentServer components, complete with environment setup, testing, and deployment instructions. Perfect for developers looking to create AI-powered currency conversion services.
Building an A2A Currency Agent with LangGraph
This guide provides a detailed explanation of how to build an A2A-compliant agent using LangGraph and the Google Gemini model. We'll walk through the Currency Agent example from the A2A Python SDK, explaining each component, the flow of data, and how the A2A protocol facilitates agent interactions.
A2A + CrewAI + OpenRouter Chart Generation Agent Tutorial
Complete tutorial for building an intelligent chart generation agent using OpenRouter, CrewAI, and A2A protocol. Master end-to-end agent development, image data handling, and A2A Inspector debugging skills with full workflow guidance from setup to deployment.
A2A JS Sample: Movie Agent
Movie information agent using A2A Protocol with TMDB API, OpenRouter AI integration, and Express.js server.