A2A Samples: LlamaIndex File Chat Agent
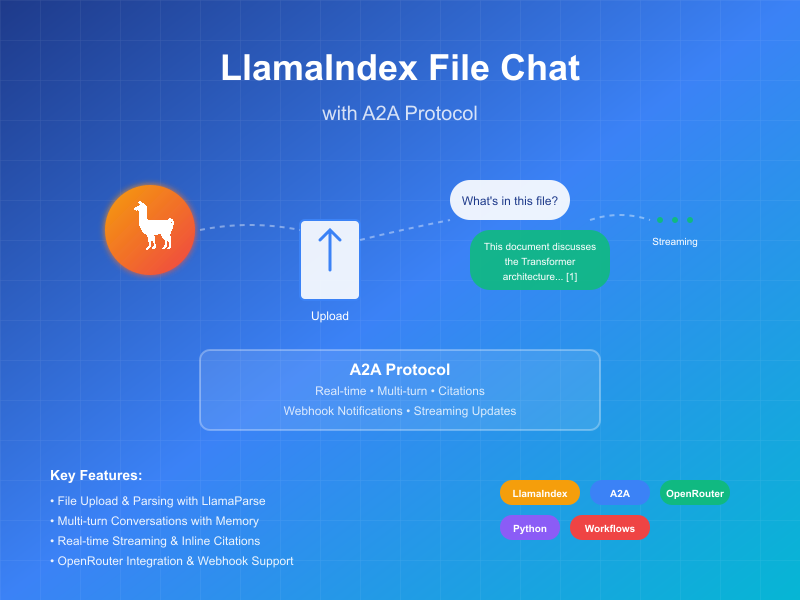
Dieses Beispiel demonstriert einen conversationalen Agenten, der mit LlamaIndex Workflows erstellt und über das A2A-Protocol bereitgestellt wird. Es zeigt Datei-Upload und -Parsing, conversationale Interaktionen mit Unterstützung für Multi-Turn-Dialoge, Streaming-Antworten/-Updates und Inline-Zitate.
Quellcode
a2a llama index file chat with openrouter
Funktionsweise
Dieser Agent verwendet LlamaIndex Workflows mit OpenRouter, um einen conversationalen Agenten bereitzustellen, der Dateien hochladen, parsen und Fragen zum Inhalt beantworten kann. Das A2A-Protocol ermöglicht standardisierte Interaktion mit dem Agenten, wodurch Clients Anfragen senden und Echtzeit-Updates erhalten können.
sequenceDiagram
participant Client as A2A Client
participant Server as A2A Server
participant Workflow as ParseAndChat Workflow
participant Services as Externe APIs
Client->>Server: Nachricht senden (mit oder ohne Anhang)
Server->>Workflow: Als InputEvent weiterleiten
alt Hat Anhang
Workflow-->>Server: Stream LogEvent "Dokument wird geparst..."
Server-->>Client: Status-Update streamen
Workflow->>Services: Dokument parsen
Workflow-->>Server: Stream LogEvent "Dokument erfolgreich geparst"
Server-->>Client: Status-Update streamen
end
Workflow-->>Server: Stream LogEvent über Chat-Verarbeitung
Server-->>Client: Status-Update streamen
Workflow->>Services: LLM Chat (mit Dokumentkontext falls verfügbar)
Services->>Workflow: Strukturierte LLM-Antwort
Workflow-->>Server: Stream LogEvent über Antwortverarbeitung
Server-->>Client: Status-Update streamen
Workflow->>Server: Finale ChatResponseEvent zurückgeben
Server->>Client: Antwort mit Zitaten zurückgeben (falls verfügbar)
Note over Server: Kontext wird für Folgefragen beibehalten
Hauptfunktionen
- Datei-Upload: Clients können Dateien hochladen und parsen, um Kontext für den Chat zu bieten
- Multi-Turn-Gespräche: Agent kann zusätzliche Informationen anfordern, wenn nötig
- Echtzeit-Streaming: Bietet Status-Updates während der Verarbeitung
- Push-Benachrichtigungen: Unterstützung für Webhook-basierte Benachrichtigungen
- Conversational Memory: Behält Kontext über Interaktionen in derselben Sitzung bei
- LlamaParse Integration: Verwendet LlamaParse für präzises Datei-Parsing
HINWEIS: Dieser Beispiel-Agent akzeptiert multimodale Eingaben, aber zum Zeitpunkt der Erstellung unterstützt die Beispiel-UI nur Texteingaben. Die UI wird in Zukunft multimodal werden, um diesen und andere Anwendungsfälle zu handhaben.
Voraussetzungen
- Python 3.12 oder höher
- UV
- Zugang zu einem LLM und API Key (Aktueller Code verwendet OpenRouter API)
- Ein LlamaParse API Key (kostenlos erhalten)
Setup & Ausführung
-
Projekt klonen und zum Verzeichnis navigieren:
git clone https://github.com/sing1ee/a2a_llama_index_file_chat cd a2a_llama_index_file_chat -
Virtuelle Umgebung erstellen und Abhängigkeiten installieren:
uv venv uv sync -
Eine Umgebungsdatei mit Ihren API-Schlüsseln erstellen:
echo "OPENROUTER_API_KEY=ihr_api_key_hier" >> .env echo "LLAMA_CLOUD_API_KEY=ihr_api_key_hier" >> .envAPI-Schlüssel erhalten:
- OpenRouter API Key: Registrieren Sie sich unter https://openrouter.ai für Ihren kostenlosen API-Schlüssel
- LlamaCloud API Key: Erhalten Sie einen kostenlos unter https://cloud.llamaindex.ai
-
Den Agenten ausführen:
# Mit uv uv run a2a-file-chat # Oder virtuelle Umgebung aktivieren und direkt ausführen source .venv/bin/activate # Unter Windows: .venv\Scripts\activate python -m a2a_file_chat # Mit benutzerdefinierten Host/Port uv run a2a-file-chat --host 0.0.0.0 --port 8080 -
In einem separaten Terminal einen A2A Client CLI ausführen:
Eine Datei zum Parsen herunterladen oder zu Ihrer eigenen Datei verlinken. Zum Beispiel:
curl -L https://arxiv.org/pdf/1706.03762 -o attention.pdf
git clone https://github.com/google-a2a/a2a-samples.git
cd a2a-samples/samples/python/hosts/cli
uv run . --agent http://localhost:10010
Und etwas Folgendes eingeben:
======= Agent Card ========
{"name":"Parse and Chat","description":"Parses a file and then chats with a user using the parsed content as context.","url":"http://localhost:10010/","version":"1.0.0","capabilities":{"streaming":true,"pushNotifications":true,"stateTransitionHistory":false},"defaultInputModes":["text","text/plain"],"defaultOutputModes":["text","text/plain"],"skills":[{"id":"parse_and_chat","name":"Parse and Chat","description":"Parses a file and then chats with a user using the parsed content as context.","tags":["parse","chat","file","llama_parse"],"examples":["What does this file talk about?"]}]}
========= starting a new task ========
What do you want to send to the agent? (:q or quit to exit): Wovon handelt diese Datei?
Select a file path to attach? (press enter to skip): ./attention.pdf
Technische Implementierung
- LlamaIndex Workflows: Verwendet einen benutzerdefinierten Workflow zum Parsen der Datei und anschließenden Chat mit dem Benutzer
- Streaming-Unterstützung: Bietet inkrementelle Updates während der Verarbeitung
- Serialisierbarer Kontext: Behält Gesprächsstatus zwischen Turns bei, kann optional in Redis, MongoDB, auf Festplatte etc. persistiert werden
- Push-Benachrichtigungssystem: Webhook-basierte Updates mit JWK-Authentifizierung
- A2A Protocol Integration: Vollständige Konformität mit A2A-Spezifikationen
Einschränkungen
- Unterstützt nur textbasierte Ausgabe
- LlamaParse ist kostenlos für die ersten 10K Credits (~3333 Seiten mit Grundeinstellungen)
- Speicher ist sitzungsbasiert und im Arbeitsspeicher, daher nicht zwischen Server-Neustarts persistiert
- Das Einfügen des gesamten Dokuments in das Kontextfenster ist nicht skalierbar für größere Dateien. Sie möchten möglicherweise eine Vektor-DB oder eine Cloud-DB bereitstellen, um Retrieval über eine oder mehrere Dateien für effektives RAG auszuführen. LlamaIndex integriert sich mit vielen Vektor-DBs und Cloud-DBs.
Beispiele
Synchrone Anfrage
Anfrage:
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Wovon handelt diese Datei?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Antwort:
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "129",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "Diese Datei handelt von XYZ... [1]"
}
],
"metadata": {
"1": ["Text für Zitat 1"]
}
"index": 0,
}
],
}
}
Multi-Turn-Beispiel
Anfrage - Seq 1:
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Wovon handelt diese Datei?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Antwort - Seq 2:
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "129",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "Diese Datei handelt von XYZ... [1]"
}
],
"metadata": {
"1": ["Text für Zitat 1"]
}
"index": 0,
}
],
}
}
Anfrage - Seq 3:
POST http://localhost:10010
Content-Type: application/json
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "130",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Was ist mit Sache X?"
}
]
}
}
}
Antwort - Seq 4:
{
"jsonrpc": "2.0",
"id": 11,
"result": {
"id": "130",
"status": {
"state": "completed",
"timestamp": "2025-04-02T16:53:29.301828"
},
"artifacts": [
{
"parts": [
{
"type": "text",
"text": "Sache X ist ... [1]"
}
],
"metadata": {
"1": ["Text für Zitat 1"]
}
"index": 0,
}
],
}
}
Streaming-Beispiel
Anfrage:
{
"jsonrpc": "2.0",
"id": 11,
"method": "tasks/send",
"params": {
"id": "129",
"sessionId": "8f01f3d172cd4396a0e535ae8aec6687",
"acceptedOutputModes": [
"text"
],
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Wovon handelt diese Datei?"
},
{
"type": "file",
"file": {
"bytes": "...",
"name": "attention.pdf"
}
}
]
}
}
}
Antwort:
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Dokument wird geparst..."}]},"timestamp":"2025-04-15T16:05:18.283682"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Dokument erfolgreich geparst."}]},"timestamp":"2025-04-15T16:05:24.200133"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"Chat mit 1 anfänglichen Nachrichten."}]},"timestamp":"2025-04-15T16:05:24.204757"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"System-Prompt wird eingefügt..."}]},"timestamp":"2025-04-15T16:05:24.204810"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"working","message":{"role":"agent","parts":[{"type":"text","text":"LLM-Antwort erhalten, Zitate werden geparst..."}]},"timestamp":"2025-04-15T16:05:26.084829"},"final":false}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","artifact":{"parts":[{"type":"text","text":"Diese Datei behandelt den Transformer, eine neuartige neuronale Netzwerkarchitektur, die ausschließlich auf Aufmerksamkeitsmechanismen basiert und völlig auf Rekurrenz und Faltungen verzichtet [1]. Das Dokument vergleicht den Transformer mit rekurrenten und Faltungsschichten [2], beschreibt die Modellarchitektur [3] und präsentiert Ergebnisse von maschinellen Übersetzungs- und englischen Konstituenten-Parsing-Aufgaben [4]."}],"metadata":{"1":["Die dominierenden Sequenz-Transduktionsmodelle basieren auf komplexen rekurrenten oder Faltungsneuronalen Netzen, die einen Encoder und einen Decoder enthalten. Die leistungsstärksten Modelle verbinden auch den Encoder und Decoder über einen Aufmerksamkeitsmechanismus. Wir schlagen eine neue einfache Netzwerkarchitektur vor, den Transformer, der ausschließlich auf Aufmerksamkeitsmechanismen basiert und völlig auf Rekurrenz und Faltungen verzichtet. Experimente mit zwei maschinellen Übersetzungsaufgaben zeigen, dass diese Modelle qualitativ überlegen sind, während sie parallelisierbarer sind und deutlich weniger Trainingszeit benötigen. Unser Modell erreicht 28,4 BLEU bei der WMT 2014 Englisch-zu-Deutsch-Übersetzungsaufgabe und übertrifft die bestehenden besten Ergebnisse, einschließlich Ensembles, um über 2 BLEU. Bei der WMT 2014 Englisch-zu-Französisch-Übersetzungsaufgabe etabliert unser Modell einen neuen Single-Model-State-of-the-Art BLEU-Score von 41,8 nach dem Training für 3,5 Tage auf acht GPUs, ein kleiner Bruchteil der Trainingskosten der besten Modelle aus der Literatur. Wir zeigen, dass der Transformer gut auf andere Aufgaben generalisiert, indem wir ihn erfolgreich auf englisches Konstituenten-Parsing sowohl mit großen als auch begrenzten Trainingsdaten anwenden."],"2":["In diesem Abschnitt vergleichen wir verschiedene Aspekte von Selbstaufmerksamkeitsschichten mit den rekurrenten und Faltungsschichten, die üblicherweise zur Abbildung einer variablen Längensequenz von Symboldarstellungen (x1, ..., xn) auf eine andere Sequenz gleicher Länge (z1, ..., zn) verwendet werden, mit xi, zi ∈ Rd, wie eine versteckte Schicht in einem typischen Sequenz-Transduktions-Encoder oder -Decoder. Um unsere Verwendung von Selbstaufmerksamkeit zu motivieren, betrachten wir drei Desiderata.",""],"3":["# 3 Modellarchitektur"],"4":["# 6 Ergebnisse"]},"index":0,"append":false}}}
stream event => {"jsonrpc":"2.0","id":"367d0ba9af97457890261ac29a0f6f5b","result":{"id":"373b26d64c5a4f0099fa906c6b7342d9","status":{"state":"completed","timestamp":"2025-04-15T16:05:26.111314"},"final":true}}
Sie können sehen, dass der Workflow ein Artefakt mit Inline-Zitaten produziert hat, und der Quelltext dieser Zitate ist in den Metadaten des Artefakts enthalten. Wenn wir weitere Antworten in derselben Sitzung senden, wird sich der Agent an die vorherigen Nachrichten erinnern und das Gespräch fortsetzen.
Mehr erfahren
Featured Products
Tools and services from the A2A ecosystem directory.



HowHeight is the most powerful free visual height comparison tool for people, animals, objects, and characters, with charts in cm and ft + in.

Turn complex PDFs into clean Markdown that people can review and AI tools can use.
Related Articles
Explore more content related to this topic
A2A Sample: Travel Planner OpenRouter
A2A implementation of Travel Planner with OpenRouter and Python a2a-sdk
Implementing CurrencyAgent with A2A Python SDK
A step-by-step guide to building a currency conversion agent with A2A Python SDK. Features detailed implementation of CurrencyAgent, AgentExecutor, and AgentServer components, complete with environment setup, testing, and deployment instructions. Perfect for developers looking to create AI-powered currency conversion services.
Building an A2A Currency Agent with LangGraph
This guide provides a detailed explanation of how to build an A2A-compliant agent using LangGraph and the Google Gemini model. We'll walk through the Currency Agent example from the A2A Python SDK, explaining each component, the flow of data, and how the A2A protocol facilitates agent interactions.
A2A Samples: Hello World Agent
A comprehensive step-by-step guide to building a Hello World agent with A2A Python SDK. Features detailed implementation of HelloWorldAgent, HelloWorldAgentExecutor, and A2AStarletteApplication components, complete with UV environment setup, dependency management, API endpoints, authentication, and testing instructions. Perfect for developers getting started with AI-powered agent services and A2A framework.
A2A + CrewAI + OpenRouter Chart Generation Agent Tutorial
Complete tutorial for building an intelligent chart generation agent using OpenRouter, CrewAI, and A2A protocol. Master end-to-end agent development, image data handling, and A2A Inspector debugging skills with full workflow guidance from setup to deployment.